Why USPTO Phonetic Search Fails – The Systematic Problems That Leave Critical Trademark Conflicts Hidden
Published by TMChecker Team on 2025-06-05
When conducting trademark searches, many professionals rely on the USPTO’s phonetic search capabilities to identify potentially conflicting marks that sound similar but are spelled differently. This isn’t just best practice—it’s legally essential. Courts consistently recognize phonetic similarity as a critical factor in likelihood of confusion analysis, making comprehensive phonetic searching a fundamental requirement for proper trademark clearance.
However, this reliance exposes a serious problem: the USPTO’s metaphone algorithm has fundamental limitations that create dangerous blind spots in trademark protection.
The Core Problem: An Algorithm That Fails Modern Needs
The USPTO’s phonetic search system employs the metaphone algorithm—a phonetic encoding system from the 1990s that systematically fails to handle the complexities of modern trademark searching. Understanding how this algorithm works reveals why it creates such significant risks.
The metaphone algorithm attempts to convert words into phonetic codes through basic rules:
- Strips out vowels (except when starting a word)
- Converts consonants into standardized codes (e.g., “PH” becomes “F”)
- Applies simplified pronunciation patterns
The critical flaw: the algorithm processes every letter as if it were pronounced. This fundamental problem means that any word with silent letters or sophisticated consonant combinations will likely be missed in searches.
This is why searching for “Fizer” completely fails to return “Pfizer”—one of the world’s most valuable pharmaceutical trademarks. The algorithm treats the silent “P” as a pronounced element, creating entirely different phonetic codes for words that sound identical to any English speaker.
 USPTO search for “Fizer” demonstrates a critical failure—“Pfizer” is completely absent.
USPTO search for “Fizer” demonstrates a critical failure—“Pfizer” is completely absent.
Systematic Failure Points
The USPTO’s phonetic search exhibits three categories of systematic failures:
Silent Letter Blindness: The algorithm’s complete inability to handle silent consonants creates massive search gaps:
- “sychology” misses “psychology”
- “Fizer” misses “Pfizer”
For industries where creative spelling is common—pharmaceuticals, technology, consumer brands—this represents a critical vulnerability.
Complex Consonant Failures: The algorithm consistently fails with sophisticated letter combinations. Clusters like “sch,” “tch,” “gh,” “gn,” and “mb” break its simplistic logic, leaving entire categories of marks invisible. Modern brand names increasingly use these complex patterns, yet the USPTO system cannot process them reliably.
Dangerous Inconsistency: Most troubling is the system’s unpredictability. You might get lucky and have “Koca-cola” return “Coca-Cola,” but similar logic fails elsewhere. This inconsistency means you never know when the system will work and when it will fail catastrophically.
The Real Cost of These Failures
These aren’t academic concerns—they’re systematic failures that create real liability:
- Hidden Conflicts: Marks with silent letters remain completely invisible, emerging only during opposition or litigation
- False Clearance: Businesses invest millions based on searches that miss obvious phonetic matches
- Professional Risk: Relying on a system with known failure points creates potential malpractice exposure
- Cascading Costs: From emergency rebranding to litigation settlements, the financial impact multiplies
When a simple search for “Fizer” can’t find “Pfizer,” the system isn’t just limited—it’s fundamentally broken for modern trademark needs.
The Solution: Machine Learning That Actually Works
tmchecker.com directly addresses these critical failures using advanced machine learning specifically trained to capture sophisticated phonetic patterns:
Comprehensive Silent Letter Detection: Our algorithms understand that “Pfizer” and “Fizer” are phonetically identical, along with thousands of other silent letter variations across multiple languages. Every possible pronunciation is captured—no exceptions.
Advanced Pattern Recognition: Machine learning excels at identifying complex consonant clusters and sophisticated letter combinations that break traditional algorithms. Whether it’s “psychology,” “gnome,” or “mnemonic,” our system recognizes how these words actually sound.
Consistent, Reliable Performance: Unlike the USPTO’s unpredictable results, tmchecker.com delivers consistent phonetic matching. If marks sound alike, we find them—every time.
Continuous Learning: Our machine learning models continuously adapt to new naming conventions, creative spellings, and emerging trademark patterns that static algorithms like metaphone can never capture.
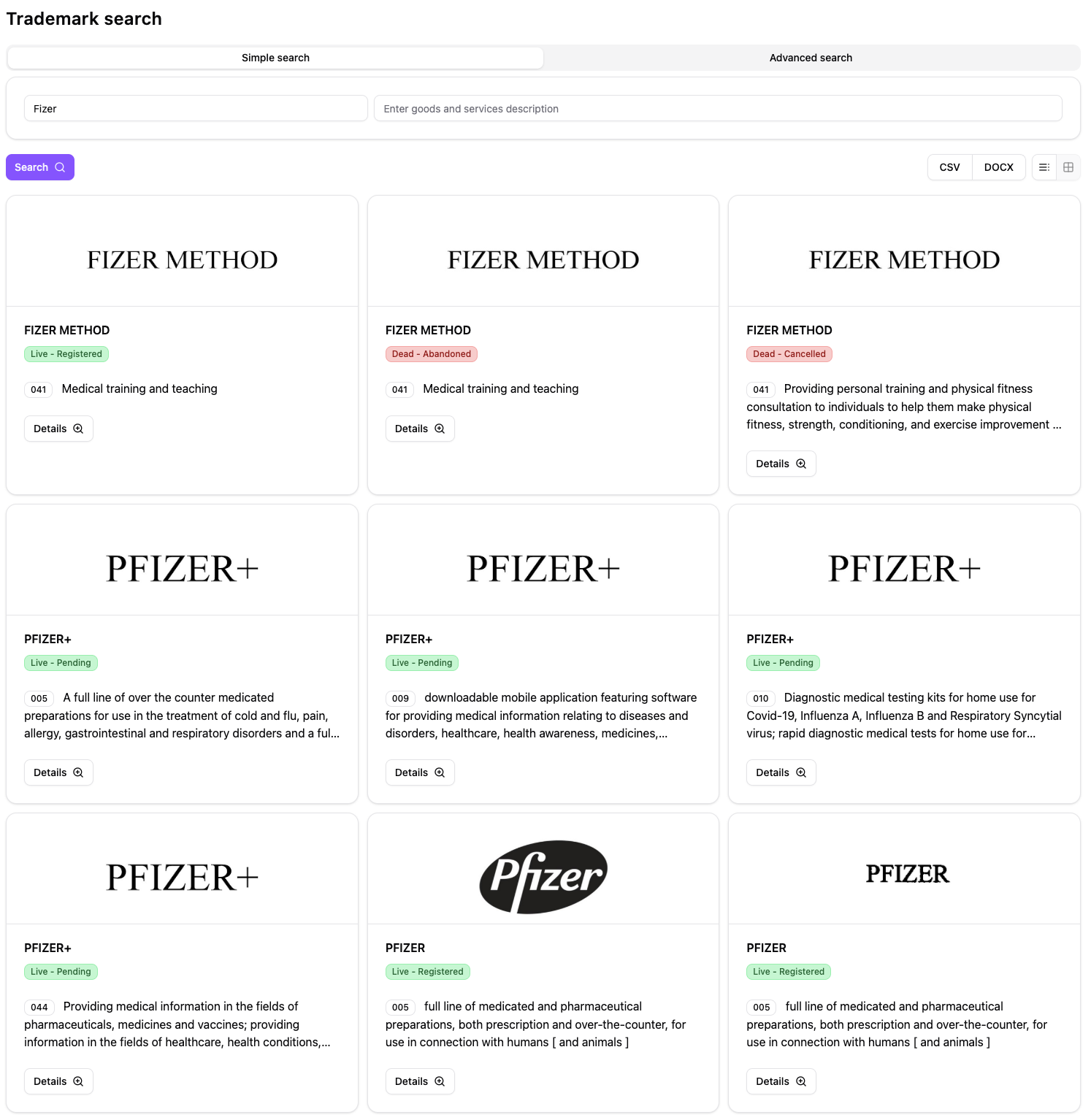 tmchecker.com instantly identifies “Pfizer” when searching for “Fizer”—along with other phonetic variations the USPTO misses.
tmchecker.com instantly identifies “Pfizer” when searching for “Fizer”—along with other phonetic variations the USPTO misses.
Why This Matters for Your Practice
The gap between what the USPTO finds and what actually exists represents unacceptable risk. Every search using only the government’s flawed algorithm is a potential liability waiting to surface.
tmchecker.com provides:
- Neural network technology that understands how words are actually pronounced
- Stronger coverage of silent letters, complex consonants, and creative spellings
- Sophisticated phonetic matching based on real pronunciation patterns
- Results you can trust for comprehensive clearance
The Bottom Line
The USPTO’s phonetic search problems aren’t minor limitations—they’re systematic failures that leave critical gaps in every search. When basic searches like “Fizer” can’t find “Pfizer,” the system demonstrates its fundamental inadequacy for modern trademark clearance.
Professional trademark searching requires tools designed for how language actually works, not how a 1990s algorithm assumes it should work. tmchecker.com fills this critical gap with machine learning that captures the sophisticated phonetic patterns the USPTO systematically misses.
In trademark clearance, what you don’t find can destroy everything you’ve built. Don’t let outdated government technology be the weak link in your search strategy.
Use tmchecker.com to experience how modern machine learning transforms phonetic trademark searching.